二叉树是 n 个结点的集合, n 为非负整数. 当 n = 0 时,
称为空二叉树; 当 n > 0 时,
二叉树由一个惟一的根结点和两棵互不相交的二叉树组成,
这两棵树分别称为二叉树的左子树和右子树;
我们也说它们是根的左子树和右子树.
我们也说左子树的根是根的左孩子, 右子树的根是根的右孩子.
二叉树的左子树和右子树是不同的,
交换以后得到的二叉树也与原来不同. 二叉树与有序树的区别是,
当有序树只有一棵子树时, 无需区分它为左子树或右子树, 但二叉树需要区分.
显然, 二叉树每个结点的度数只能是 0, 1 或 2.
同理可对满 m 叉树的结点从 1 开始, 从上到下, 从左到右地编号. 考虑编号为 i 的结点的第一个子结点 (假设存在), 它必然紧接在根结点以及前 i-1 个结点的全部子结点后, 因此前面有 1 + m(i-1) 个结点, 应当编号为 2 + m(i-1). 于是编号为 i 的结点的第 k 个子结点 (如果存在) 编号为 1 + k + m(i-1). 编号为 i 的结点的双亲结点 (如果存在) 编号为 ⌊(i-2)/m⌋ + 1. 在这个编号下, 结点 i 是其双亲的最右子结点当且仅当 (i-1) % m == 0.
上面提到的非空树的性质, 也适用于非空的二叉树.
设二叉树的结点数为 n > 0, 则边数为 n-1, 又设 0, 1, 2 度点数分别为
`n_0, n_1, n_2`, 则
`n = n_0 + n_1 + n_2`,
`n-1 = n_1 + 2 n_2`.
相减得
`n_0 - n_2 = 1`.
顺序存储 将二叉树的编号 i 的结点存储于数组的 i-1 单元. 适合完全二叉树的存储.
二叉链表存储 用指针 root 指向根结点,
left, right 指针分别指向左右子树的根.
struct BinaryTreeNode: Type val BinaryTreeNode *left, *right BinaryTreeNode *root
父指针存储 每个结点都指向其父结点, 根结点的父指针为 -1.
struct ParentBinaryTree: int root # 根结点下标 Type val[N] int parent[N]
三叉链表存储 在二叉链表中增添指向父结点的指针.
二叉树的遍历是指, 以某一种次序恰好访问二叉树的每个结点一次. 其它意义的遍历, 如列出所有根到叶的路径, 不在此列.
二叉树的广度优先遍历
设二叉树的根的地址是 root, visit
是访问结点的一个函数.
算法使用一个队列, 每次访问一个结点后, 将其两个子结点入队.
亦可在入队前 (代码中出现三次入队操作) 判断指针是否为空,
这样从队列中取出的指针就一定非空.
levelorder(root, visit()): queue.enqueue(root) while queue: root = queue.dequeue() if root: visit(root) queue.enqueue(root->left) queue.enqueue(root->right)
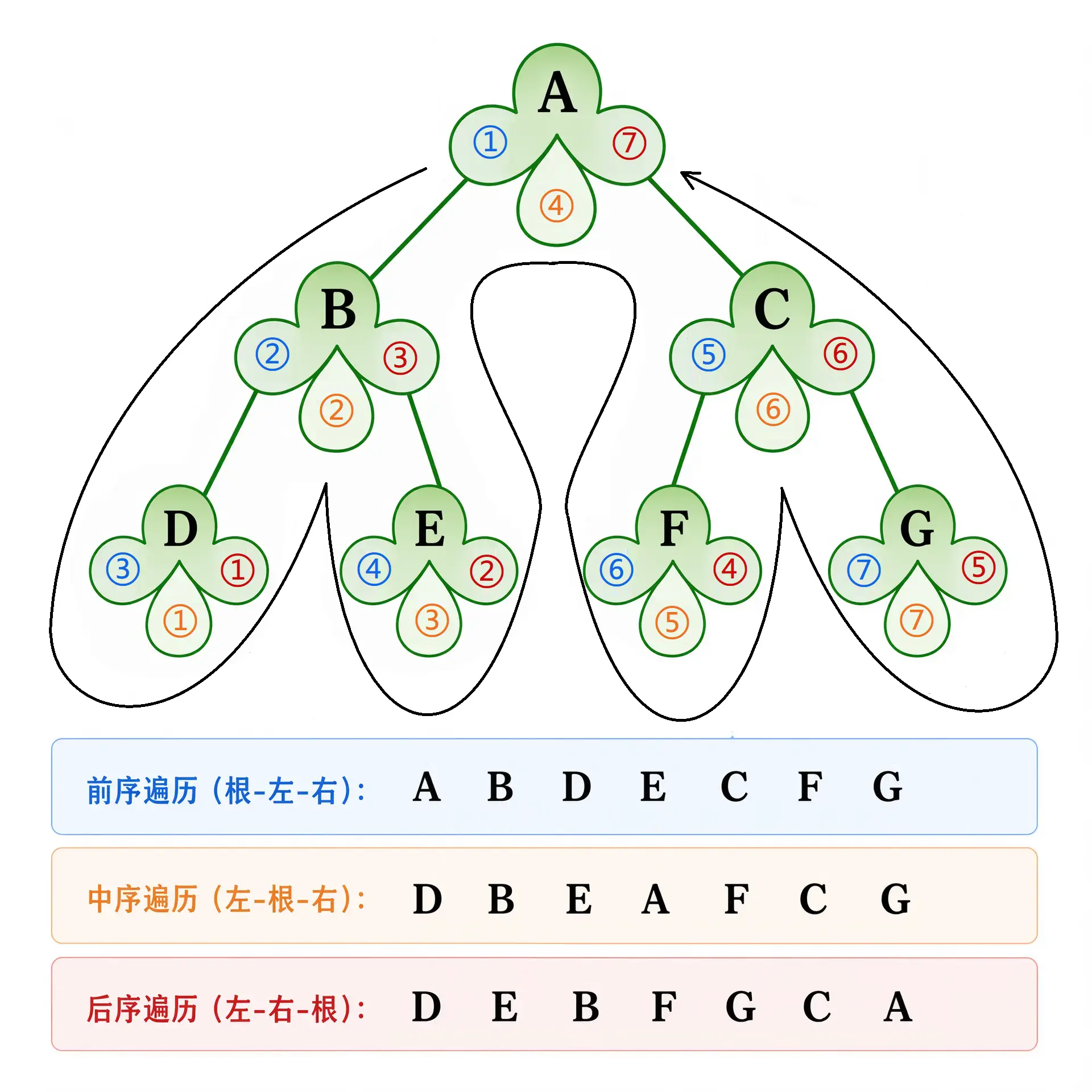
形象记忆 想象二叉树的每个结点是三叶草的形状, 就像倒置的 ♣ 一样. 我们从根出发, 沿整个图形逆时针描边. 让每个结点左边, 下边和右边的叶子分别对应于二叉树的前序, 中序和后序遍历, 按照遇到叶子的先后次序, 就分别得到前序, 中序和后序遍历的结果.
叶结点在三种深度优先遍历中出现的次序是一样的.
二叉树的递归深度优先遍历 从二叉树遍历的定义可以立即得出其递归算法. 前序遍历二叉树的代码如下; 中序遍历和后序遍历, 只要把访问根结点的次序作相应调整即可.
preorder_rec(root, visit()): if root: visit(root) preorder_rec(root->left) preorder_rec(root->right)
二叉树的非递归深度优先遍历 (三位一体)
查看原文
事实上, 我们可以利用栈来巧妙模拟递归算法, 从而写出相应的非递归算法.
秘诀在于把将要执行的动作按照一定的次序放入栈中, 再依次取出执行.
这里要执行的动作有两种: 一是访问一个结点,
二是将此结点展开为三个结点, 即它自身及其左子结点和右子结点,
再按一定的次序入栈. 显然动作一就是我们的 visit 函数,
而动作二 (以前序为例) 定义如下:
unfold(root): stack.push(root->right, 展开) stack.push(root->left, 展开) stack.push(root, 访问)
由于栈后进先出的性质, 应当将元素逆序入栈.
一同进栈的还有一个布尔变量,
它用来标识我们应当继续执行展开动作还是访问结点,
因为每个结点只需展开一次, 所以当我们第二次从栈中取出同一个结点时,
就应当访问它. 前序遍历的全部代码如下. 同理,
中序和后序遍历只需把核心的 unfold
动作的三行代码调整一下次序即可.
preorder_nonrec(root, visit()): stack.push(root, True) while stack: root, should_unfold = stack.pop() if root: if should_unfold: stack.push(root->right, True) stack.push(root->left, True) stack.push(root, False) else: visit(root)
遍历二叉树的非递归算法的一个优势是,
如果用自己实现的顺序栈, 则可以实现对工作栈的随机访问,
比如, 从栈底开始输出访问过的结点序列, 或者计算两个结点间的路径长度等.
另一个优势是, 如果要在二叉树中查找某个结点, 并返回它的值时,
递归算法需要逐层返回, 而非递归算法直接返回即可.
此外, 适当地书写非递归的中序和后序算法
(见下文非递归深度优先遍历的其它写法), 可以使得访问到每个结点时,
栈中保存的是根到该结点的路径, 这有利于处理关于结点祖先的问题.
(事实上, 上面的 preorder_nonrec 算法中, 访问到每个结点时,
栈中的全体 should_unfold == False
的结点组成该结点的全体祖先).
与下文的其他非递归写法相比, "三位一体" 算法的时空代价较大.
二叉树的遍历是许多算法的基础. 下面举一例.
删除二叉树 删除了左, 右子树后, 便可以删除根结点. 因此采用后序遍历.
remove(&root): if root: remove(root->left) remove(root->right) delete root root = NULL
从遍历序列惟一确定二叉树 已知遍历二叉树的前序序列和中序序列, 或者已知后序和中序序列, 或者已知层序和中序序列, 都可以惟一确定这棵二叉树.
以前序序列和中序序列为例. 对结点数 n 进行归纳, n = 1 时显然可以确定惟一的二叉树. 假设小于 n 时前序序列和中序序列可以惟一确定二叉树, 则对于含 n 个结点的二叉树, 取出前序序列的第一个结点, 它是根结点; 在中序序列中找到根结点, 把中序序列分成前后两部分, 分别是左, 右子树的中序序列. 从而也可以分别确定左, 右子树的前序序列. 由归纳假设, 左, 右子树可以惟一确定, 从而整棵二叉树被惟一确定.
给定遍历二叉树的前序序列和后序序列, 可以确定结点的祖先-子孙关系. m 是 n 的祖先当且仅当在前序序列中 m 在 n 之前, 且在后序序列中 m 在 n 之后.
从遍历二叉树的前序序列与后序序列无法惟一确定二叉树, 如前序为 A B C, 后序为 C B A 的二叉树有 4 棵 (下图). 但假如把这四棵二叉树看成一般的树, 则它们是相同的, 这是因为二叉树总是区分左右子树, 而树在只有一棵子树时, 不区分其左右.
A A A A
/ / \ \
B B B B
/ \ / \
C C C C
设 m, n 是二叉树的两个不同结点, 且它们之间不是祖先与后代的关系, 又设 r 是这两个结点的最近共同祖先, 则这两个结点一个在 r 的左子树中, 一个在 r 的右子树中.
显然 r ≠ m, r ≠ n. 假设结论不成立, 则 m, n 在 r 的同一子树中, 不妨设为左子树. 那么 r 的左子结点也是 m, n 的共同祖先, 且它离 m, n 更近. 矛盾.
right 指针一路向下;
left 指针一路向下;
给定二叉树遍历的一个前序序列 1..n, 则所有可能的中序序列恰好和以 1..n 为进栈序列的所有可能出栈序列一一对应. (证明?)
给定二叉树遍历的一个前序序列 1..n, 则与之对应的不同二叉树共有 `C_n` 个, `C_n` 是第 n 个 Catalan 数.
由前序序列和中序序列惟一确定二叉树可知, 这个数字就是以 1..n 为进栈序列的可能出栈序列数.
left
指针到达的最远结点, 未必是叶子结点), 结束于最右下结点 (类似).
每个结点在遍历中的下一结点是其右子树的最左下结点, 若右子树为空,
则不便计算; 其上一结点是左子树的最右下结点, 若左子树为空,
同样不便计算.
中序线索二叉树 (Inorder Threaded Binary Tree)
left_thread == True 时, left
中存储指向上一结点的线索, 否则 left 指向左子结点;
right_thread 类似. 构造中序线索二叉树时,
只需让原先二叉树中的空指针域改指向结点的前驱/后继,
并正确填写两个标志位即可.
从上面的讨论中容易得出在中序线索二叉树中计算结点前驱/后继的算法.
在实际中, 中序线索二叉树较其他两种为常用.
struct InThreadNode: Type val InThreadNode *left, *right bool left_thread, right_thread
前序线索二叉树结点 (Preorder Threaded Binary Tree Node) 标志位的意义同上. 注意到计算前驱结点, 需要用到父结点的信息, 因此前序线索二叉树需要一个指向父结点的指针域, 即它是基于三叉链表的. 后序线索二叉树与前序的情形类似.
struct PreThreadNode: Type val PreThreadNode *left, *right, *parent bool left_thread, right_thread
二叉树的中序线索化
在中序遍历的过程中完成线索化. 函数 inorder
可以实现为递归的, 也可以非递归. 前驱指针 prev
设为全局变量是最方便的, 也可以作为函数的引用参数传入.
引入的头结点既是遍历起点, 也是终点.
inorder_threading(InThreadNode *root): # 引入头结点, ? 处可以填任意值 head = prev = new InThreadNode(?, NULL, NULL, False, False) # 任一版本的中序遍历 inorder(root, visit) # 此时 prev 已经到达中序终点, 我们将它连接到 head visit(head) return head visit(root): root->left_thread = !root->left if root->left_thread: root->left = prev prev->right_thread = !prev->right if prev->right_thread: prev->right = root prev = root
从深度优先遍历二叉树的形象记忆法中得知, 前序遍历, 中序遍历与后序遍历访问结点的时机分别是在遇到结点时, 从左子树返回时和从右子树返回时. 另一方面, 上节对三种遍历次序下的后继结点的讨论, 也对非递归算法的编写很有帮助. 本节给出的算法效率高于先前给出的 "三位一体" 型的非递归遍历算法.
非递归前序遍历 在栈底设置空指针作为哨兵. 访问根元素后, 在进入左子树前, 先令右子树的根入栈, 这样左子树访问完毕后就能顺利进入右子树.
preorder_nonrec1(root, visit()): stack.push(NULL) while root: visit(root) if root->right: stack.push(root->right) if root->left: root = root->left else: root = stack.pop()
非递归中序遍历
先顺 left 指针走到头, 保存途经的结点序列 n1, n2, ..., nk;
找到中序遍历起点 nk. 接着对序列 nk, ..., n1 进行访问.
每访问一个结点后, 立即以中序访问其右子树.
每访问到一个结点, 栈中保存的都是从根到该结点的路径.
inorder_nonrec1(root, visit()): while True: if root: stack.push(root) root = root->left elif stack: root = stack.pop() visit(root) root = root->right else: break
下面的写法很奇怪, 不建议这样写.
inorder_nonrec2(root, visit()): stack.push(root) while stack: root = stack.top() if root: stack.push(root->left) # 向左走到尽头 else: stack.pop() # 空指针出栈 if stack: root = stack.pop() visit(root) stack.push(root->right)
非递归后序遍历
后序遍历起点是左下方的第一个叶子结点, 为了找到它, 需要先沿
left 走到尽头, 如果不是叶子结点, 则进入右子树继续搜索.
这个过程中途经的结点全部保存在栈中. 但这个路线是 "弯曲" 的,
因此有必要用 bool 变量标明退栈前的位置. 如果是从左子树返回则为 L,
这时应当进入右子树搜索其后序起点; 从右子树返回则为 R,
这时应当访问结点并弹栈, 这里通过清空指针的方式来实现弹栈操作.
每访问到一个结点, 栈中保存的都是从根到该结点的路径.
postorder_nonrec1(root, visit()): while True: if root: stack.push(root, L) root = root->left elif stack: root, from = stack.pop() if from == L: stack.push(root, R) root = root->right else: # from == R visit(root) root = NULL # 清空指针, 以便弹栈 else: break
用 pre 记录最近访问的结点, 比上一个算法更省空间.
postorder_nonrec2(root, visit()): pre = NULL while True: if root: stack.push(root) root = root->left elif stack: root = stack.pop() if root->right != pre: # 刚从左子树返回 stack.push(root) root = root->right else: # 从右子树返回, 应当访问 visit(root) pre = root root = NULL # 清空指针, 以便弹栈 else: break
树的长子-兄弟表示 (二叉链表表示) 每个结点的两个链域分别指向其第一个子结点和下一个兄弟结点. 这一表示法的理论依据是, 二叉树与森林可以建立一一对应. 亦可在二叉链表中增添指向父结点的指针, 注意这不同于二叉树的三叉链表.
struct TreeNode: Type val TreeNode *first_child, *next_sibling
树的父指针表示
将树的 N 个结点连续存储. 每个结点带有指向父结点的指针.
用 -1 表示不存在父结点.
struct ParentTree: int root # 根结点下标 Type val[N] # 数据域 int parent[N] # 父指针
树的孩子链表表示
将树的 N 个结点连续存储. 每个结点后连接一链表,
表中装着各个子结点的下标. 这个数据结构类似于图的邻接表,
但是在树当中几乎没有用.
struct ChildListNode: int child ChildListNode *next struct ChildTree: int root Type val[N] ChildListNode *child_list[N]
利用二叉树与森林的一一对应容易得到: 遍历树 (森林) 的先根序列和后根序列惟一确定这棵树 (这座森林). 这是树 (森林) 和二叉树的一个显著区别.
并查集
用数组 parent[N] 表示含 N 个元素的森林,
每个子集合的根结点的父指针域存储该集合中元素数目的负值.
假设下面各个函数的参数 i, j
等均落在合法范围 0..N-1 内.
int parent[N] has_parent(i): return parent[i] >= 0 # 求 i 所在集合的根 find(i): while has_parent(i): i = parent[i] return i # 合并以 i, j 为根的集合, 将小的并入大的 union(i, j): if abs(parent[i]) < abs(parent[j]): swap(i, j) parent[i] += parent[j] parent[j] = i
可以证明, 按 union 得到的集合树深度不超过
`|__log n __|+1`, 其中 `n` 是树中的结点总数, `log` 是以 2
为底的对数. 注意到集合中有 `n` 个元素时, 至多进行 `n-1` 次并操作,
从而应用 union 和 find
解决等价类问题的时间复杂度为 `O(n log n)`.
`n = 1` 的结论是平凡的. 设结论对所有小于 `n` 的正整数成立, 考察 `n` 的情形. 不妨设此树是由含 `m` 个结点的树 `S` 和含 `n-m` 个结点的树 `T` 合并而成的, 且 `1 le m le n//2`, `n-m ge 1`. 若 `"depth"(S) lt "depth"(T)`, 则合并后的树深等于 `"depth"(T)`, 由假设, `"depth"(T) le |__ log(n-m) __| +1 lt |__ log n __| + 1`. 若 `"depth"(S) ge "depth"(T)`, 则合并后的树深等于 `"depth"(S) + 1 le |__ log m __| + 1 + 1 = |__ log(2m) __| + 1 le |__ log n __| + 1`.
压缩路径查找 在并查集中求根结点的同时, 把所有沿途结点都变为根结点的直接子结点, 树的深度将进一步减小. 下面给出非递归与递归两个版本.
find_and_compress(i): r = find(i) while i != r: next = parent[i] parent[i] = r i = next return r find_and_compress_rec(i): if !has_parent(i): return i return parent[i] = find_and_compress_rec(parent[i])
Ackermann 函数定义为两个非负整数 `m, n` 的函数: `A(m, n) = { n+1, if m = 0; A(m-1, 1), if m gt 0 and n = 0; A(m-1, A(m, n-1)), otherwise; :}` 已经证明, 利用压缩算法的并查集解决等价类问题的时间复杂度为 `O(n alpha(n))`, 其中 `alpha(n)` 为一元 Ackermann 函数 `A(x, x)` 的拟逆, 即 `alpha(n) = min{x: A(x, x) ge n}`. 由于一元 Ackermann 函数增长得非常快, 可以想见 `alpha(n)` 增长缓慢.